An insight into Vietnamese syllables usage
As Vietnamese uses Latin alphabet with extra characters for its writing system, it’s easy and common to mix English into the text. This is prone to be problematic for language processing systems as not only they need to take care of the source language but also be aware of other foreign words that might appear.
tl;dr
By analyzing content published in 2015 and 2016 of 5 popular Vietnamese news sources, I found that there are only 7184 unique syllables (download) are actually used and they cover more than 94% of the content. And here is a cool graphic.

Vietnamese most popular syllables cloud
Data
To analyze the usage of Vietnamese, 5 websites were chosen as they are among the most popular online news and have consistent data available in 2015 and 2016. As Vietnamese syllables is the focus, some categories (egs: world news, technology, automobile,…) were removed as they might have a high amount of foreign words.
Number of articles published in 2015 and 2016 from 5 Vietnamese news websites
| url | 2015 | 2016 | total | |
|---|---|---|---|---|
| tuoitre | http://tuoitre.vn | 34362 | 32760 | 67122 |
| vov | http://vov.vn | 33683 | 36666 | 70349 |
| vietnamnet | http://vietnamnet.vn | 31634 | 33353 | 64987 |
| dantri | http://dantri.vn | 53026 | 53775 | 106801 |
| vnexpress | http://vnexpress.net | 50310 | 53740 | 104050 |
Data are normalized by removing abnormal characters, fixing encoding, … before process to the next step. I used a self-developed normalization pipeline for this task. Its details would not be laid out here as the amount of content can be it’s own post.
Instead of combining data into one big text corpus, each site was analyzed separately as it might reveal some interesting information. For statistic, the content of each sites were gathered, paragraph was splitted into sentences, then sentences were splitted into tokens. Tokens were classified into three groups:
- VI: Vietnamese passing tokens. The list of all Vietnamese syllables was used with addition of these 5 syllables:
đắk,lắk,đăk,lăk,konas they are vastly common. - NU: tokens that have at least one number in it, egs:
2015,IPv6,GMT+7, … This group would be mostly ignored by my statistic. - OT: tokens that do not belong to either VI or NU. We can expect this group contains several classes and would be the main challenge for Vietnamese languages processing systems.
The frequencies of each unique tokens (from now I would call them ‘vocabs’) are caculated from text corpora. As mention before all vocabs belong to NU group are removed. However, instead of take all unique tokens into account we would only care about the ones that appeared at least several times. Depend on the sites I chose different frequency limit, the ideas were to get just above 20000 vocabs from each website.
Analytics
Vietnamese syllables VI and the other vocabs OT statistic results
| Frequency limit | #VI | #OT | VI coverage | VI only sentences | OT once sentences | |
|---|---|---|---|---|---|---|
| tuoitre | 4 | 6235 | 14210 | 94.26% | 48.12% | 33.63% |
| vov | 4 | 6446 | 14557 | 94.76% | 49.98% | 30.71% |
| vietnamnet | 7 | 6199 | 15239 | 94.08% | 49.00% | 32.81% |
| dantri | 9 | 6297 | 14360 | 93.40% | 48.53% | 35.56% |
| vnexpress | 7 | 5834 | 15394 | 94.50% | 53.32% | 30.06% |
| combined | 7184 | 34003 | 94.09% | 49.67% | 33.23% |
All 5 sites shows similar pattern in every measurement, this give us more confident in our results. The most important result here is the number of Vietnamese syllables that were actually used, all 5 sites have about 6000 syllables but when combined we have 7184 unique syllables. While the number of syllables is small they cover more than 94% of all tokens used in these articles.
The figure below give more information about the Vietnamese syllables usage. We can see that a small amount of the top syllables cover most of the contents. For language learners the top 2000 syllables can be used as learning matterial as they cover more than 90% of everyday uses.
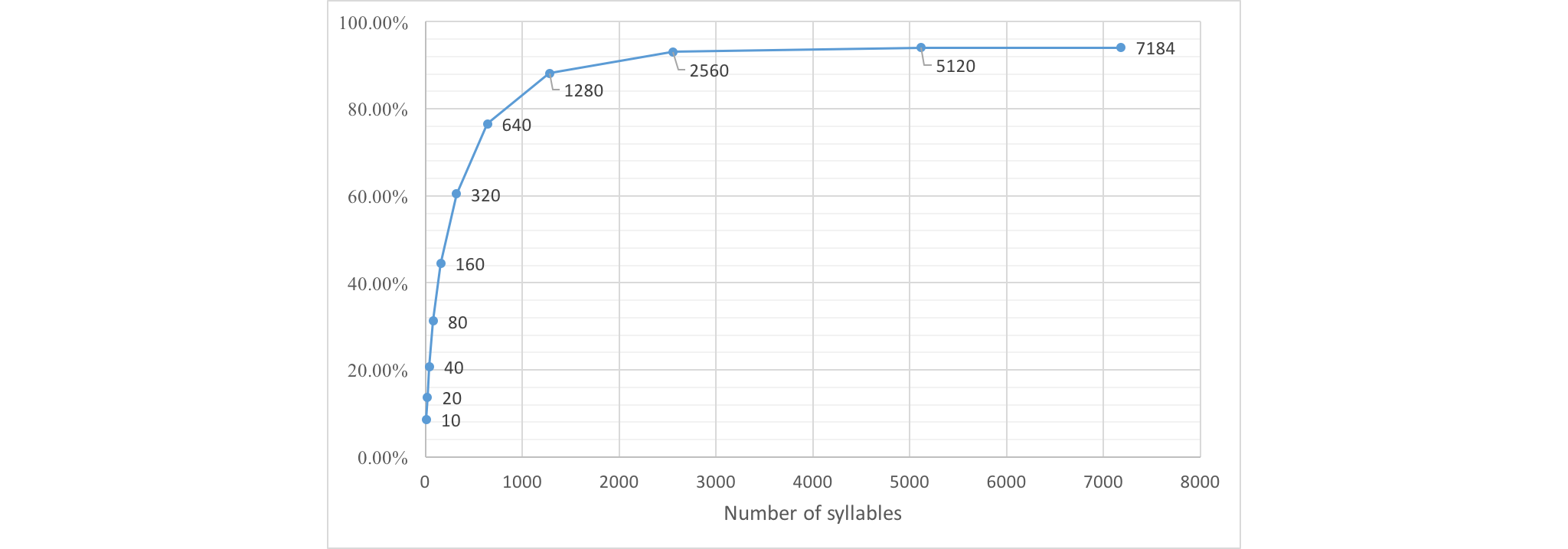
Coverage of top Vietnamese syllables
For language processing systems is it safe to just handle Vietnamese syllables? The answer is it depends. Even though 7184 syllables cover more than 94% of all occurences, there are just about 50% of all sentences contains Vietnamese-only vocabs. Simply speaking in case of Automatic Speech Recognition if you manage to train a perfect recognizer but they only handle Vietnamese syllables you can achieve 94% syllable accuracy while at most 50% sentence accuracy. So you should decide which is more important for your project.
To develop more sophisticate systems for Vietnamese, an in-dept analytic on out-of-domain vocabs would be very valuables. Although that analytic would not be given in this post, I could provide some initial observation based on the results I got here. By combining all 5 sites we get 34,000 OT vocabs which are the most popular non-vietnamese-syllables. These vocabs are appeared on more than 30% of all sentences and belongs to several different classes:
- Initialism:
TPHCM,UBND,Đ,Q, … - Tone-stripped syllables:
NGUYEN,NGOC,PHUONG, … - Vietnamized words:
ÔTÔ,SÔCÔLA,CANÔ, … - Foreign words and names:
INTERNET,SHOW,TAXI,OBAMA…
And don’t forget all the symbols (mathematic, currency,…) which has been removed earlier in the normalization step. To develop a Vietnamese language processing system there are more than just Vietnamese syllables you need to worry about.
Conclusion
Since Internet has became a common utility for Vietnamese people, the Vietnamese language has evolved and adapted to a new era of globalization, which means more foreign words, more internet slangs and spelling error. To develop competitive Vietnamese language processing systems, you need to be aware of the real life usage of Vietnamese language instead of just basing on textbook and assumptions.
Related post