Unicode character categories and the CJK ideograph complications
As most programming languages use ASCII characters for keywords, it is a common practice to normalize text to ASCII to reduce unexpected behaviors. While this works great for English, it is problematic for other languages as this process discards useful information. To develop a robust natural language processing (NLP) system that works with native scripts, we can look at Unicode, a well-established universal character encoding, and the way it handles multi-lingual problems. Specifically, Chinese, Japanese and Korean are the main focus.
tl;dr
Each unicode character is classified into one of 30 general categories: Lu Ll Lt Lm Lo Mn Mc Me Nd Nl No Pc Pd Ps Pe Pi Pf Po Sm Sc Sk So Zs Zl Zp Cc Cf Cs Co Cn. These categories, again, can be grouped into seven groups: Letter, Mark, Number, Punctuation, Symbol, Separator, and Other. Knowing the category of a unicode character reveals its intented usage. These meta information is especially useful for Chinese, Japanese, and Korean (CJK) as they have a large amount of logographic characters many of which are obscure, legacy, or obsolete.

Unicode character properties
Each Unicode character is embedded with lots of information about the way a system should handle them, in this post we focus on the general category of a character. You can check the properties of a character using online utilities (e.g., 漢 character properties), or within popular programming language (e.g., python unicodedata module). The online tool is especially useful to quickly check characters mentioned in this post. The following table lists all Unicode general categories and several reprentative characters with a focus on English, Chinese, Japanese, Korean, and Vietnamese. Depend on your web browser, some characters will fail to render and just show a rectangle.
Unicode Character General Categories
| ID | Name | Notable examples |
|---|---|---|
| Letter | ||
| Lu | Letter, uppercase | A B C 𝐴 𝑩 𝒞 Ψ Ӧ Ồ Đ A B |
| Ll | Letter, lowercase | a b ӧ ồ đ a b ᴀ ᴁ ᴂ ᵭ ᴪ |
| Lt | Letter, titlecase | Dž Dz ᾮ |
| Lm | Letter, modifier | ʰ ʷ ᴭ ᵆ ᵟ ˮ ᵣ ᵩ 々 〴 〻 ゞ |
| Lo | Letter, other | 漢 汉 あ ぁ ア ア 〆 한 글 ᄒ ᅡ |
| Mark | ||
| Mn | Mark, nonspacing | |
| Mc | Mark, spacing combining | |
| Me | Mark, enclosing | |
| Number | ||
| Nd | Number, decimal digit | 0 1 2 3 0 1 2 3 |
| Nl | Number, letter | Ⅰ Ⅱ Ⅳ Ⅸ ⅱ ⅲ ⅳ ⅸ 〣 〸 |
| No | Number, other | ¹ ¼ ② ⓺ ❺ ⑾㆔ ㈦ ㉏ ㉙ ㊃ |
| Punctuation | ||
| Pc | Punctuation, connector | _ _ |
| Pd | Punctuation, dash | - - 〜 |
| Ps | Punctuation, open | ( [ { 「 『 ( [ { 【 《 |
| Pe | Punctuation, close | ) ] } 」 』 ) ] } 】 》 |
| Pi | Punctuation, initial quote | ‘ ‛ “ ‟ |
| Pf | Punctuation, final quote | ’ ” |
| Po | Punctuation, other | ' " ! * , . / : ; ? \ 。 、 ‧ |
| Symbol | ||
| Sm | Symbol, math | + < = > | ~ × ÷ ∀ ∈ ∉ ∑ |
| Sc | Symbol, currency | $ £ ¥ € ₩ ₫ |
| Sk | Symbol, modifier | ^ ` ` |
| So | Symbol, other | ©️ ®️ ™ ★ ♬ ⼎ ⼓ ⺡ 😀 😅 😟 |
| Separator | ||
| Zs | Separator, space | _ _ ← space _ _ ← Ideographic space |
| Zl | Separator, line | |
| Zp | Separator, paragraph | |
| Other | ||
| Cc | Other, control | |
| Cf | Other, format | |
| Cs | Other, surrogate | |
| Co | Other, private use | |
| Cn | Other, not assigned |
General category is a good indication to the intent usage of a Unicode character, especially if it a puntuation or a symbol. However, it is not as informative when the character is a logograph as most of them belong the Letter, other category.
For extra information about the character, we can look at the Block property. A Unicode Block is a range of code points used for a specific language or a functional component. For example, Hiragana Unicode Block ranges from U+3040 to U+309F contains Hiragana characters used in Japanese written language. Or the Latin Extended Additional Unicode Block includes extra diacritic latin characters that are used for Vietnamse and other languages.
Note that, knowing the intented usage of a character does not guarantee it is its usage in a specific context, as people may use it in a way that is different from its intended purpose (e.g., / and * are used as math symbols even though they are puntuations), incorrectly, or simply just as a decoration.
Unicode and CJK languages
漢 字 汉 字 ひ ら が な カ タ カ ナ 한 글
This section includes several random stories about the way Unicode handles CJK languages, they are interesting case studies that are useful for the development of any type of multilingual systems (focus on CJK). They are also fascinating stories overall, so if you are interested in language and/or software engineer it is worth a read.
Disclaimer: I am not a linguist and not even fluent in Chinese, Japanese, or Korean. The following stories are just introductions to these problems, from the software engineering point of view. Readers are encouraging to open linked urls for more information about each particular story.
CJK Unified Ideographs
漢 字
Chinese characters are not only used in Chinese but also in Japanese and Korean (and Vietnamese, historically). Even though, the same character can look slightly differrent in each CJK languages, Unicode encodes them using a single code point, this effort is generally refered to as Han unification, or Unihan.
These characters are contained within the CJK Unified Ideographs Unicode Block and its extensions. Note that, Hiragana, Katakana, and Hangul are not included in these blocks.
As several language variations are encoded in a same code point, the duty to render correct glyphs is transfered to the typeface (or font) uses for the task.
Source Hans Serif and its sister Source Hans Sans are rare open source Pan-CJK typefaces, a project of Adobe and Google. They are vastly useful assets for multilingual designers any user of the involved languages. Despite the unification effort, many variations with significant difference are encoded in two separated code points (e.g., 漢 and 汉). These Han characters cover a big segment of the Lo category.
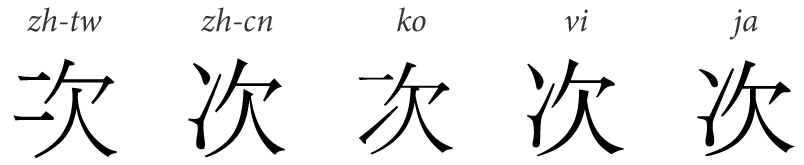
CJKV ideograph 次 in traditional and simplified Chinese, Korean, Vietnamese and Japanese
(By Betoseha - Own work, CC BY-SA 3.0, Link)
Chữ Nôm (Vietnamese former logographic writing system)
𡨸 喃 T i ế n g V i ệ t
Chữ Nôm is a former Vietnamese writing system based on Chinese characters to represent Sino-Vietnamese (Hán-Việt) vocabulary and native Vietnamese words. Many new characters were also created using various methods (e.g., 𡨸 - Unihan). Modern Vietnamese writing system (Chữ Quốc Ngữ, litterally National Scripts) uses Latin and Latin extended additional characters, which belong to Lu and Ll categories while many Nôm characters can be found in CJK Unified Ideographs block or its extensions and belonged to Lo category. While it is no longer a part of mordern Vietnamese language, Chữ Nôm is still used for decorations or in historical/ceremonial contexts.
Halfwidth (katakana) and Fullwidth (ASCII) characters
「 カ タ カ ナ 」 A S C I I ! a s c 1 2 3
CJK glyphs are fullwidth characters (written within a square), while typical Latin characters are halfwidth (written within a rectangle). Mixing fullwidth and halfwidth characters in a single sentence can look quite jarring so the need for fullwidth ASCII characters when used along CJK scripts. In the other hands, early Japanese computing uses single-byte to encode katanaka and render them at the same (half) width as other ASCII characters, so there is a demand for halfwidth katakana for compatible purposes. Halfwidth and Fullwidth Forms Unicode Block contains the varitational glyphs that deal with this particular problem. It includes fullwidth forms of ASCII characters, halfwidth forms of katakana, and also halfwidth forms of Hangul Jamo. Each of these characters belong to the same category as their respective original.
Hangul Jamo (Korean alphabet letters represent consonants and vowels)
ᄒ ᅡ ᆫ ᄀ ᅳ ᆯ ᄌ ᅡ ᄆ ᅩ
Unicode precomposes common Hangul (Korean alphabet) syllables into Unicode ‘characters’, each of these syllables contains positional forms of the consonants and vowels. Hangul Jamo is the Unicode Block contains the positional forms of these components, while Hangul Compatibility Jamo is the non-positional and compatible with South Korean national standard. You can copy the positional jamo characters listed above into a note taking app and see them dynamically combine into syllables. They can also be used to compose syllables that are not precomposed by Unicode but the ability to render such syllables are highly depended on the typeface at used. These jamos belong to Lo category.
Kangxi radicals (Or how to look up Chinese characters)
⼀ ⼄ ⼈ ⼎ ⼓ ⼟ ⼤ ⼩ ⼰ ⼷
Kangxi radicals is a the most popular radical system of Chinese characters, it is used in dictionaries to quickly look up Chinese characters. Unicode has the Kangxi radicals block for these radicals and CJK Radicals Supplement block for several variants. These radical code points belong to the So category. For many of these radicals, there are no visual difference with their respective “character” counterpart (e.g., 小 is a character belongs to Lo while ⼩ is a radical belongs to So). The recommended usage is always using the radical code points when refers to radicals as it provides extra information for machine processing. However, such behavior is not guaranteed in practices (e.g., jisho.org).
Mojibake (Garbled text due to unintended character encoding)
譁?ュ怜喧縺 Tiếng Việt
Mojibake is the phenomenon that garbled text are rendered instead of expected text, it is the result of mismatch between the character encoding and decoding methods. It is relevant to CJKV and other languages, but it is most prominent in Japan, hence the name mojibake (文字化け). The reason is that Japanese has many encoding standards, of which Shift-JIS is the second-most popular, just below Unicode encoding standards like UTF-8. Similarly, Chinese language has Big5 and GB 2312, while Korean has EUC. Even modern Vietnamese, which uses an extended Latin alphabet, has several local character encoding schemes such as VNI and VSCII. Even though Unicode, and UTF-8 more specifically, dominates online content as the multilingual standard nowaday, knowing about the existing of local encoding schemes will help handling many unexpected situations.
Conclusion
Developing a NLP system for CJK languages is quite challenging especially for non-native developers as they are quite different from English. By utilizing a well-established standard for text, Unicode in this case, we can greatly reduce the complexicity and establish a reasonable scope for the project. Simply extracting linguistic information embedded in a Unicode character will reveal its intended usage and many useful information on how a computing system should handle them. However, these information is just for reference as we cannot expect users to always follow the suggested usage. So strategies to handle unintended scenarios are crucial for robust NLP systems.